
고정 헤더 영역
상세 컨텐츠
본문 제목
[스노피 AI] Vision Transformer 쉽게 이해하기 - 6.Multi-Head Attention in Vision Transformers
본문

Multi-Head Attention in Vision Transformers
1. Introduction to Multi-Head Attention
- Definition: Multi-Head Attention은 모델이 입력 시퀀스의 여러 부분에 동시에 집중할 수 있도록 하는 Transformer 아키텍처의 핵심 구성 요소입니다. ViT(Vision Transformers)에서는 다양한 이미지 패치를 병렬로 처리하고 연관시키는 데 사용되므로 모델이 시각적 데이터의 다양한 측면을 캡처할 수 있습니다.
- Importance: 여러 개의 Attention Head를 사용함으로써 모델은 입력에 대한 더욱 풍부하고 다양한 표현을 학습할 수 있어 이미지 인식 및 분할과 같은 작업에서 더 나은 성능을 얻을 수 있습니다.
2. Concept of Multi-Head Attention
- Single Attention Head: 쿼리(Q), 키(K) 및 값(V) 벡터의 단일 세트에 대한 attention점수를 계산하는 작업이 포함됩니다.
- Multi-Head Mechanism: 각각 고유한 Q, K 및 V 벡터 세트가 있는 여러 주의 헤드를 병렬로 실행하여 이를 확장하여 모델이 다양한 관점에서 정보를 캡처할 수 있도록 합니다.
3. Multi-Head Attention Mechanism
- Process:
- Linear Projections: 입력 임베딩은 서로 다른 학습된 가중치 행렬을 사용하여 Q, K, V 벡터의 여러 세트로 투영됩니다.
- Attention Calculation: Q, K, V 벡터의 각 세트는 자체 주의 점수를 계산하고 V 벡터의 가중 합계를 출력합니다.
- Concatenation: 모든 attention head의 출력이 연결됩니다.
- Final Linear Projection: 연결된 출력은 최종 선형 투영을 통과하여 multi-head attention 매커니즘의 최종 출력을 생성합니다
4. Mathematical Formulation
- Input Projections:
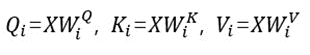
-
- X는 입력이고 WiQ, WiK, WiV는 i 번째 head에 대한 가중치 행렬입니다.
- Attention Calculation:

- Concatenation and Final Projection:

-
- WO는 최종 투영 행렬이고, h는 head 개수입니다.
5. Advantages of Multi-Head Attention
- Parallelism: 모델이 입력의 여러 측면을 동시에 처리하여 효율성과 표현력을 향상시킬 수 있습니다.
- Rich Representations: 각 attention head는 입력의 다양한 부분에 집중할 수 있어 더욱 미묘하고 자세한 표현이 가능합니다.
- Flexibility: 모델은 다양한 attention head의 정보를 결합하여 데이터의 광범위한 패턴과 관계를 학습할 수 있습니다.
6. Multi-Head Attention in Vision Transformers
- Application:
- Image Patches: ViT에서 이미지 패치는 토큰으로 처리되며, 다중 헤드 주의를 통해 모델은 서로 다른 패치를 서로 연결하고 글로벌 컨텍스트와 공간 관계를 캡처할 수 있습니다
- Efficiency: 모델이 이미지의 여러 영역에 동시에 초점을 맞출 수 있도록 하여 대규모 이미지를 처리하는 데 도움이 됩니다.
7. Example Calculation
2개의 attention head와 3개의 Token input sequence가 있는 예를 살펴보겠습니다.
7.1. Input Embeddings
- Tokens: 벡터로 표현된 3개의 토큰입니다.
7.2. Linear Projections
- Head 1:
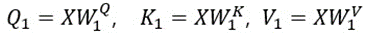
사진 설명을 입력하세요.
- Head 2:

7.3. Attention Calculation
- Head 1:

- Head 2:

7.4. Concatenation and Final Projection
- Concatenate Outputs:
Concat(Attention1, Attention2)
- Final Output:
Output=Concat(Attention1, Attention2)WO
8. Challenges and Considerations
- Computational Complexity: 여러 Attention Head를 병렬로 실행하면 계산 비용이 증가할 수 있습니다..
- Memory Usage: 각 헤드에 대해 여러 개의 Q, K, V 벡터를 저장해야 하므로 메모리 사용량이 늘어납니다.
9. Summary
- Key Takeaways: Multi-Head Attention은 시각적 데이터에서 복잡한 관계를 포착하는 모델의 기능을 향상시키는 Vision Transformers의 강력한 메커니즘입니다. 여러 개의 주의 헤드를 병렬로 처리함으로써 모델은 입력의 다양한 측면에 동시에 집중할 수 있어 더욱 풍부하고 정확한 표현이 가능해집니다.
SnowPea-VS
SnowPea-VS(Video Studio)에 텍스트 또는 이미지를 입력하여 여러분이 원하는 영상을 만들어보세요! 대기자 명단 등록 SnowPea-VS(Video Studio)에 텍스트 또는 이미지를 입력하여 여러분이 원하는 영상을 만
www.wafour.com






댓글 영역