
고정 헤더 영역
상세 컨텐츠
본문
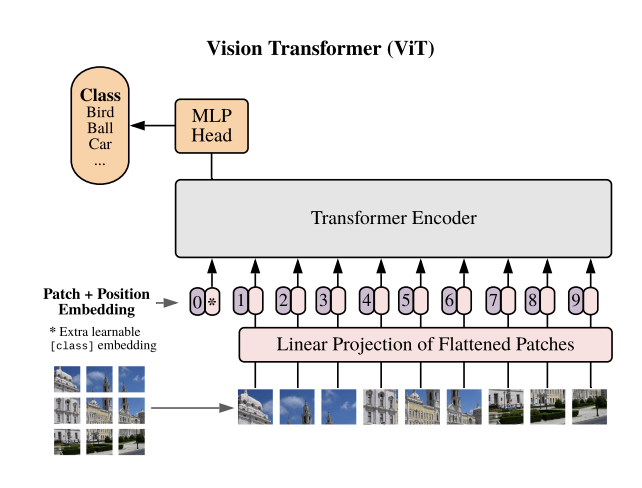
Vision Transformer (ViT)는 이미지 인식 및 컴퓨터 비전 분야에서 최근 각광받고 있는 기술입니다. ViT는 기존의 Convolutional Neural Networks (CNN) 대신 Transformer 모델을 사용하여 이미지를 처리합니다. 다음은 Vision Transformer의 주요 기술을 10개의 카테고리로 정리한 내용입니다.
1. Transformer Architecture
- Transformer는 Self-Attention 메커니즘과 피드포워드 네트워크로 구성됩니다. 이 구조는 원래 NLP 분야에서 제안되었으나, ViT에서는 이미지를 처리하는 데 사용됩니다. 각 레이어는 인코더와 디코더로 나뉘며, ViT에서는 인코더 부분만 사용됩니다.
2. Patch Embedding
- 이미지 입력은 고정 크기의 패치로 나누어집니다. 각 패치는 벡터로 변환되어 임베딩 됩니다. 이는 텍스트의 단어를 임베딩하는 것과 유사합니다. 패치 임베딩은 이미지를 작은 조각으로 분할하여 각 조각을 고유한 임베딩 벡터로 변환합s니다.
3. Positional Encoding
- Transformer 모델은 순차적 데이터를 처리하지 않기 때문에 입력 데이터의 순서를 인식하기 위해 위치 인코딩을 사용합니다. 패치 임베딩에 위치 정보를 추가하여 모델이 각 패치의 위치를 인식할 수 있도록 합니다.
4. Self-Attention Mechanism
- Self-Attention은 입력 데이터의 각 부분이 다른 모든 부분과의 관계를 학습할 수 있게 합니다. 이를 통해 각 패치 간의 상호작용을 모델링하여 이미지 내의 중요한 특징을 학습합니다.
5. Multi-Head Attention
- Multi-Head Attention은 여러 개의 독립적인 Self-Attention을 병렬로 수행합니다. 이를 통해 다양한 관점에서 패치 간의 관계를 학습할 수 있습니다. 각 헤드는 다른 부분에 집중하여 더 풍부한 표현을 제공합니다.
6. Feed-Forward Neural Networks
- Self-Attention 레이어 다음에는 피드포워드 신경망이 있습니다. 이는 각 패치 임베딩 벡터에 비선형 변환을 적용하여 특징을 추출합니다. 피드포워드 네트워크는 두 개의 선형 변환과 하나의 ReLU 활성화 함수로 구성됩니다.
7. Layer Normalization
- Layer Normalization은 모델의 각 레이어에서 입력 데이터를 정규화하여 학습의 안정성을 높입니다. 이는 Batch Normalization과 유사하지만, 배치 크기에 독립적입니다.
8. Classification Token
- ViT에서는 분류를 위해 특별한 클래스 토큰([CLS])이 사용됩니다. 이 토큰은 다른 패치들과 함께 입력되어 최종 레이어에서 이미지의 전체 정보를 요약하여 분류 작업에 사용됩니다.
9. Pre-training and Fine-tuning
- ViT 모델은 대규모 데이터셋에서 사전 학습(pre-training)되고, 이후 특정 작업에 맞게 파인 튜닝(fine-tuning)됩니다. 이는 모델이 일반적인 특징을 학습한 후, 특정 작업에 특화된 특징을 학습할 수 있게 합니다.
10. Applications and Performance
- ViT는 이미지 분류, 객체 탐지, 세그멘테이션 등 다양한 컴퓨터 비전 작업에 적용됩니다. ViT는 특히 대규모 데이터셋에서 우수한 성능을 보이며, CNN 기반 모델과 비교하여 효율성과 정확성에서 큰 발전을 이루었습니다.
이와 같이 10개의 카테고리로 ViT의 주요 기술을 정리하면, ViT의 구조와 작동 원리를 체계적으로 이해하는 데 도움이 될 것입니다. 다음에는 위에서 정리한 ViT 주요 기술들을 세부적으로 정리하여 소개하겠습니다.
SNOWPEA AI
상상만으로 만드는 새로운 세상, 스노피 AI가 여러분을 초대합니다. 텍스트만으로 여러분의 상상을 영상으로 만들어보세요. 스노피 AI는 영화, 애니메이션, 광고 등 모든 분야의 영상을 쉽고 빠
www.wafour.com
'SnowPea(스노피) AI' 카테고리의 다른 글
| [스노피 AI] Vision Transformer 쉽게 이해하기 - 3. Patch Embedding in Vision Transformers (0) | 2024.06.20 |
|---|---|
| [스노피 AI] Vision Transformer 쉽게 이해하기 - 2. Transformer Architecture (1) | 2024.06.13 |
| [스노피 AI] 딥러닝에서 활성화함수(Activation Function) 쉽게 이해하기 (0) | 2024.06.03 |
| [스노피 AI] 퍼셉트론(Perceptron) 쉽게 이해하기 (0) | 2024.06.03 |
| [스노피 AI] 디퓨전 모델(Diffusion model)에 대한 쉬운 설명 (1) | 2024.06.03 |






댓글 영역