SnowPea(스노피) AI
[스노피 AI] Vision Transformer 쉽게 이해하기 - 4. Positional Encoding in Vision Transformers
와포
2024. 6. 26. 17:07

Positional Encoding in Vision Transformers
1. Introduction to Positional Encoding
- Definition: 위치 인코딩은 Transformer 모델의 입력 임베딩에 위치 정보를 주입하는 데 사용되는 기술입니다. Transformer는 본질적으로 입력 시퀀스의 순서를 캡처하지 않으므로 위치 인코딩은 시퀀스 내의 요소 위치에 대해 필요한 컨텍스트를 제공합니다.
- Importance: ViT(Vision Transformers)에서 위치 인코딩은 이미지 패치에 대한 공간 정보를 유지하는 데 매우 중요합니다.
2. Why Positional Encoding is Needed
- Transformers and Order: 순환 신경망(RNN)과 달리 변환기는 입력 시퀀스의 모든 요소를 동시에 처리합니다. 이 병렬 처리는 시퀀스 요소의 순서를 유지하지 않습니다.
- Spatial Information: 이미지의 경우 시각적 맥락을 이해하기 위해서는 패치의 공간적 배열을 유지하는 것이 필수적입니다.
3. Types of Positional Encoding
- Absolute Positional Encoding: 입력 임베딩에 추가된 고정 위치 인코딩을 사용합니다.
- Relative Positional Encoding: 시퀀스 요소 간의 상대적 거리를 인코딩합니다.
- Learnable Positional Encoding: 위치 정보를 인코딩하기 위해 훈련 중에 적응하는 훈련 가능한 매개변수입니다.
4. Absolute Positional Encoding
- Formula: 위치 인코딩은 다양한 주파수의 사인 및 코사인 함수를 사용하여 정의됩니다.

여기서 pos는 위치이며, i는 차원(dimension) 인덱스입니다.
5. Relative Positional Encoding
- Description: 절대 위치를 인코딩하는 대신 상대 위치 인코딩은 시퀀스 요소 간의 상대적 거리를 캡처하므로 일부 작업에서 더 효과적일 수 있습니다.
- Application: 절대 위치보다 상대 위치가 더 중요한 작업에 유용합니다.
6. Learnable Positional Encoding
- Description: 위치 정보를 나타내기 위해 훈련 과정 중에 학습된 훈련 가능한 벡터입니다.
- Advantage: 작업 및 데이터 세트의 특정 요구 사항에 적응할 수 있습니다.
7. Applying Positional Encoding in Vision Transformers
- Process:
- Patch Embeddings: 이미지 패치를 임베딩으로 변환합니다.
- Add Positional Encodings: 각 패치 임베딩에 위치 인코딩을 추가합니다.
- Sequence of Embeddings: 임베딩된 시퀀스는 Transformer 모델에 입력됩니다.
8. Example Calculation
간단한 시퀀스에 대한 절대 위치 인코딩의 예를 살펴보겠습니다.
8.1. Input Sequence
- Length: 5 positions.
- Embedding Dimension: 4 dimensions.
8.2. Positional Encoding Calculation
- Position 0:

- Position 1:
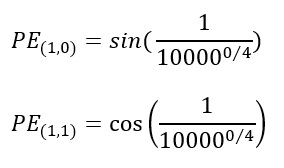
9. Advantages and Challenges
9.1. Advantages
- Order Awareness: Transformer 모델에 필수 주문 정보를 제공합니다.
- Flexibility: 작업에 따라 다양한 유형의 위치 인코딩을 선택할 수 있습니다.
9.2. Challenges
- Complexity: 위치 인코딩을 적절하게 설계하고 통합하면 모델에 복잡성이 추가될 수 있습니다.
- Adaptability: 고정 위치 인코딩은 모든 작업에 잘 적용되지 않을 수 있으므로 학습 가능한 인코딩을 사용해야 합니다.
10. Summary
- Key Takeaways: 위치 인코딩은 Transformer 모델, 특히 공간 정보가 핵심인 Vision Transformer에서 순서 정보를 유지하는 데 중요합니다. 절대, 상대, 학습 가능 인코딩과 같은 다양한 유형의 위치 인코딩은 다양한 애플리케이션에 유연성을 제공합니다.